Поиск в твиттере по геокоду на примере COVID-кризиса в Южной Азии
Твиттер может служить ценным источником информации для исследования открытых источников, причем не только отдельных пользователей, но и для понимания более обширных трендов. В недавнем материале Bellingcat наша техническая расследовательская команда изучила паттерны данных Твиттера, чтобы продемонстрировать серьезность и нарастание коронакризиса в Индии.
Твиттер часто используется как источник данных для анализа социальных сетей, поскольку посты по умолчанию публичны, что обеспечивает легкий доступ для исследователей. Однако одно из его ограничений — относительная редкость геолокационных данных. В наши дни очень мало твитов содержат точные геоданные, поскольку пользователи должны добавлять их вручную. Однако есть альтернативный способ поиска места публикации твитов: геокодированный поиск.
Используя результаты множества геокодированных запросов, команда Bellingcat смогла построить примерную карту географического распределения твитов с просьбами о немедленной помощи в Индии и в соседних странах Южной Азии, во многих из которых также наблюдается коронавирусный кризис. Также мы нанесли на карту процент твитов, где используется ключевое слово «кислород», которые могут коррелировать с недостатком медицинского кислорода.
Метод сбора этих данных подробно описан далее в этом материале. Также ниже приведен исходный код, который можно адаптировать для других проектов. В процессе сбора этих данных мы заметили некоторые особенности результатов поиска по Твиттеру. Они также перечислены ниже. Из-за этих особенностей точная интерпретация этих данных имеет некоторые оговорки. Географическое позиционирование не является точным. Также количество старых твитов можно оценить только приблизительно. Оценочные данные не следует напрямую сравнивать с неоценочными. Кроме того, как мы отмечали в нашем апрельском материале, англоязычные посты в Твиттере — по своей природе ограниченная и нерепрезентативная выборка, поскольку в регионе используется большое количество различных социальных сетей и языков. Однако для начала необходимо понять, как можно искать и собирать посты в твиттере по геолокации.
Геореференсинг твитов
Некоторые твиты содержат точную информацию о широте и долготе, которую можно получить с помощью API Твиттера. Для его использования необходим API-ключ, однако он доступен для всех с помощью Портала разработчика Twitter. Однако сюда входят только те геоданные, которые пользователи сами добавляют в твиты, а популярность этой опции в последнее время упала. Поиск по геокоду позволяет пользователям Твиттера находить твиты в пределах указанного расстояния от конкретной широты и долготы и показывает даже те твиты, где нет явной информации о широте и долготе.
Например, поисковый запрос ‘geocode:13.08,80.27,100km’ (как показано на скриншоте ниже) выдает твиты, которые, как полагает Твиттер, были опубликованы в пределах 100 километров от индийского города Ченнаи (который расположен на указанных координатах 13.08º с.ш., 80.27º в.д.). Полный список продвинутых поисковых операторов см. в этом документе, который ведет Игорь Бригадир.
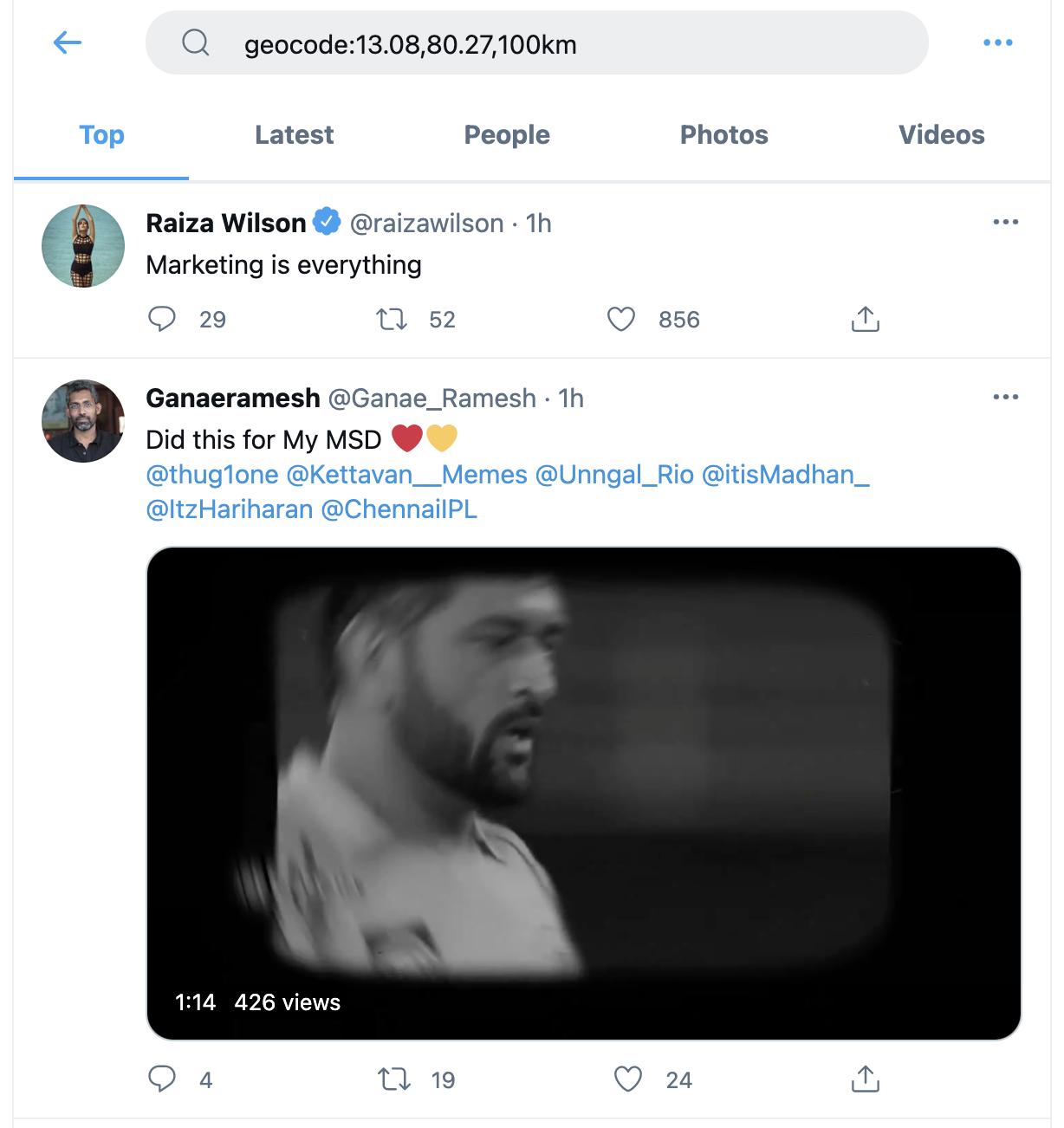
Пример результатов поиска по геокоду
Использовав множество поисков по геокоду, распределенных по некой территории. можно составить примерную картину географического распределения некой темы или ситуации, оценив как количество твитов, так и распределение их содержания. Например, на скриншоте ниже видно распределение твитов со словами «помогите» и «срочно» от 25 апреля 2021 года по Индии и соседним регионам Южной Азии. В центре каждого круга — координаты геокодированного запроса.
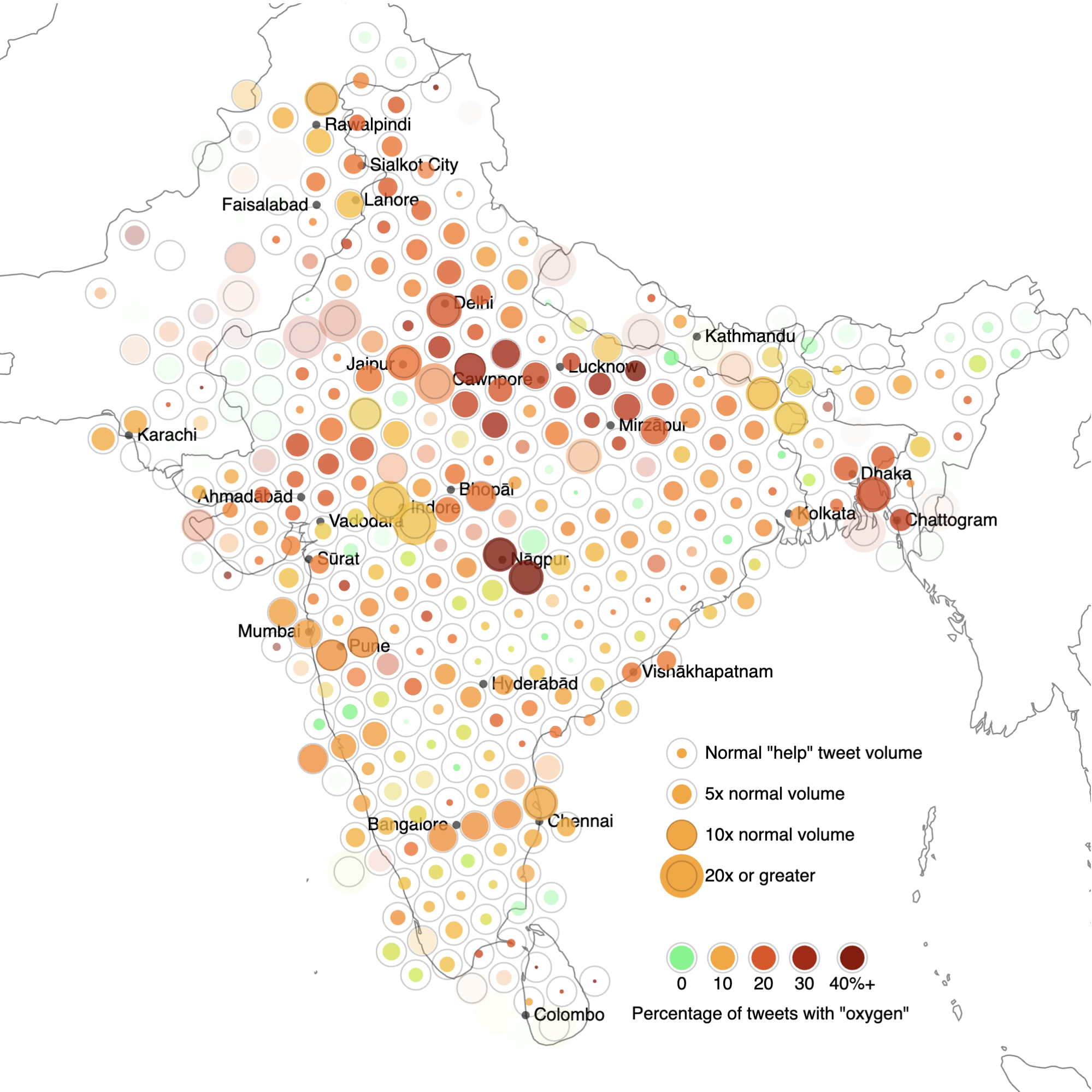
Карта геолокации постов со словами «помогите» или «срочно» в Индии и соседних странах. Цвет каждой точки показывает, какой процент этих постов также содержит ключевое слово «кислород»
Карта создана посредством подсчета результатов сотен геокодированных поисковых запросов, которые были собраны с помощью TWINT и Python TWINT — это полезный инструмент для сбора данных из Твиттера. С его помощью можно быстро получить тысячи и даже миллионы твитов. TWINT использует веб-интерфейс продвинутого поиска и автоматически собирает твиты в готовый для анализа формат (например, CSV). Инструкции по установке и примеры см. в репозитории TWINT на Github.
Поскольку TWINT не использует официальный API Твиттера, для его использования не требуется API-ключ, а также на него не действуют ограничения. Это облегчает автоматический поиск по множеству геотегов. Эта методология, которая также использовалась для создания визуализации в начале этой статьи, подробнее описана ниже. Исходный код также опубликован в Jupyter — интерактивной среде для написания Python-скриптов.
При этом важно отметить, что точность этих данных ограничена точностью оценки места публикации твита самим Твиттером. Кроме того, не вполне очевидно, как функция поиска по геокоду в Твиттере определяет место публикации каждого твита. Эксперименты и наблюдения технической команды расследования Bellingcat показали, что эти данные, по-видимому, происходят из двух источников — твитов с тегом «места», а также локации, которую пользователи выставляют у себя в профиле. Твиттер может использовать и другие источники географической информации, например IP-адрес пользователя или данные браузера, которые пригождаются, например, для таргетированной рекламы. Однако, по-видимому, эта информация не используется при геокодированном поиске.
Важно, что информация о местоположении в профиле пользователя используется только для позиционирования твитов за последнюю неделю (около 7-8 дней). В результате создается впечатление, будто недавних твитов гораздо больше, чем опубликованных более недели назад. Среди недавних твитов есть как твиты с добавленным тегом «место», а также твиты, где такого тега нет, в то время как среди старых твитов есть только твиты с таким тегом.
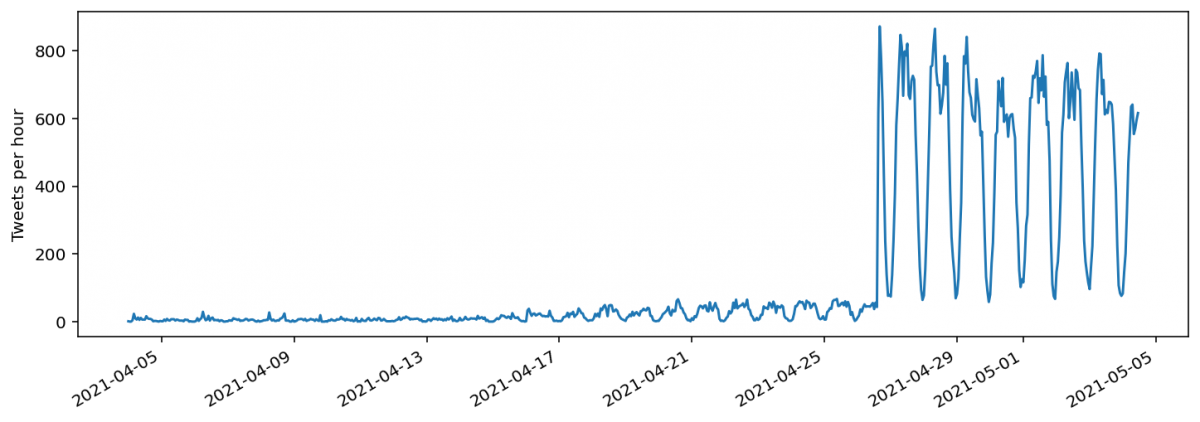
Данные TWINT — те же, что показываются при ручном поиске в веб-интерфейсе продвинутого поиска. Официальные API Твитттера имеют некоторые отличия. Команда Bellingcat сравнила их друг с другом, проверив отличия собранных данных. Имеется несколько API Твиттера. Мы использовали как бесплатный Standard Twitter API (v1.1), так и платный Premium Twitter API. Twitter Premium Search API возвращает два типа данных: отдельные твиты, соответствующие запросу, а также количество твитов, которые соответствуют запросу за некоторый временной интервал.
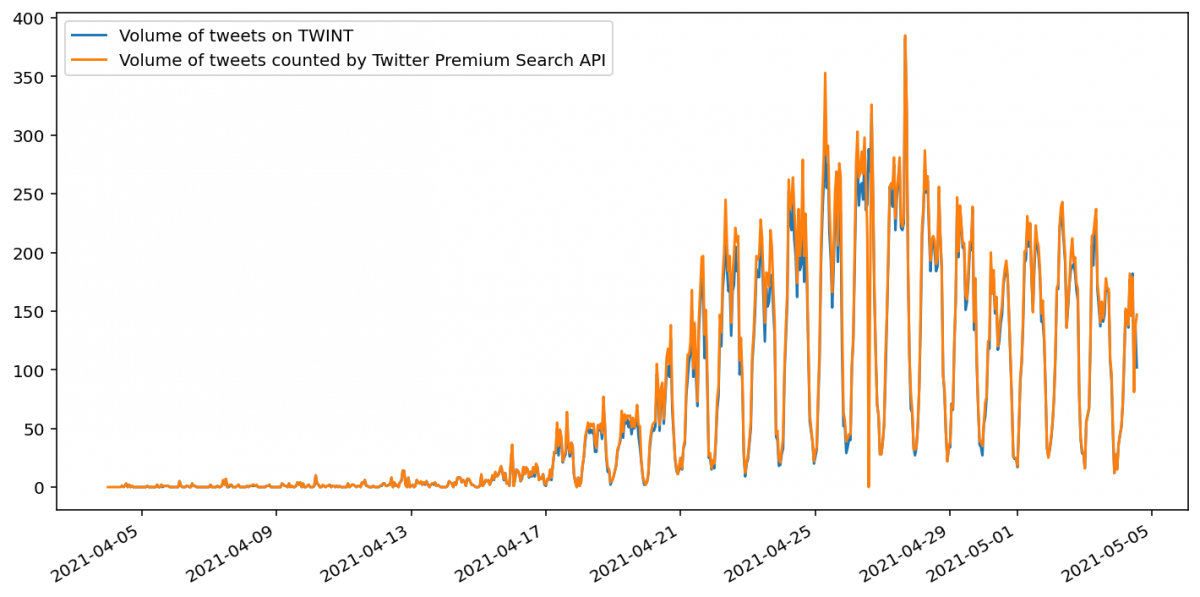
В случае простого поиска в Твиттере (т.е. без геокода в запросе) число твитов, которые находят TWINT и Twitter API, практически совпадает. Однако при этом Twitter Premium Search API насчитывает, по-видимому, чуть больше твитов, чем TWINT. В документации Твиттера говорится, что это ожидаемое поведение, поскольку API может считать твиты, которые не видны из-за настроек безопасности или удалены.
При геокодированном поиске TWINT находит гораздо больше твитов за последнюю неделю, но раньше этого промежутка времени количество твитов вновь почти совпадает. Кроме того, все твиты, которые возвращает Twitter Premium Search API, имеют тег «места». Это означает, что при поиске по геокоду Twitter Premium Search API не использует информацию о местоположении из профиля Твиттера, в отличие от продвинутого поиска в веб-интерфейсе.
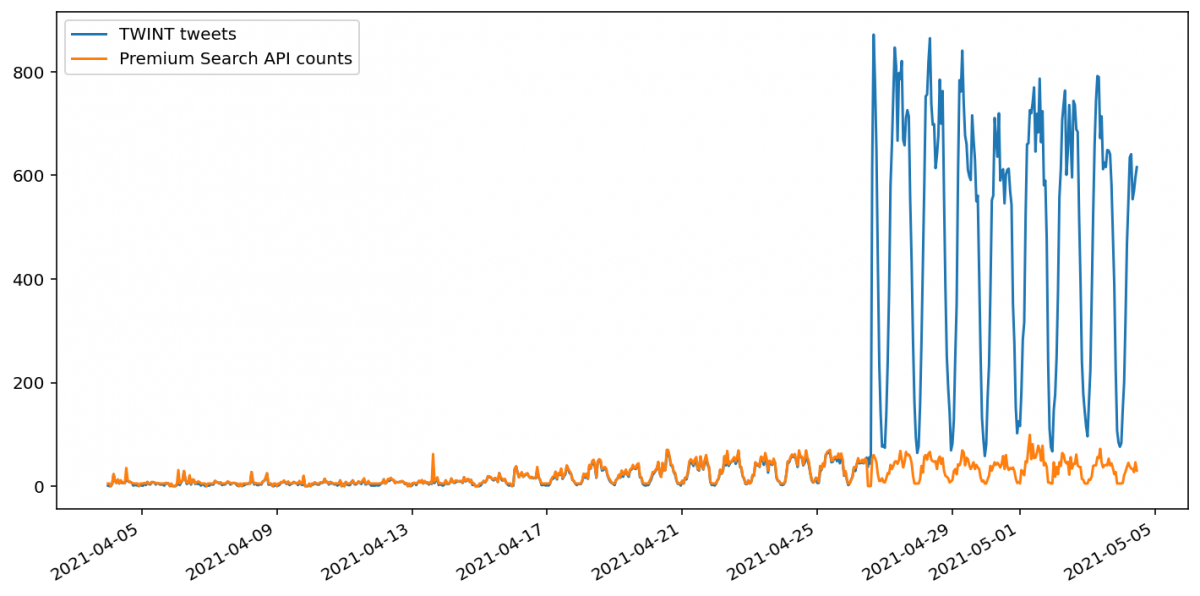
Должен быть возможен анализ только тех твитов, где указано определенное «место», однако возможность сбора этих данных в TWINT в настоящее время не работает. Это означает, что непосредственно сравнить старое и новое количество твитов невозможно. В коде визуализации на Jupyter есть грубая коррекция умножением, однако такой подход следует считать крайне приблизительным.
Также следует отметить, что Twitter Premium API, по-видимому, округляет вверх до пяти любое число от одного до пяти твитов. Ноль, судя по всему, остается нолем.
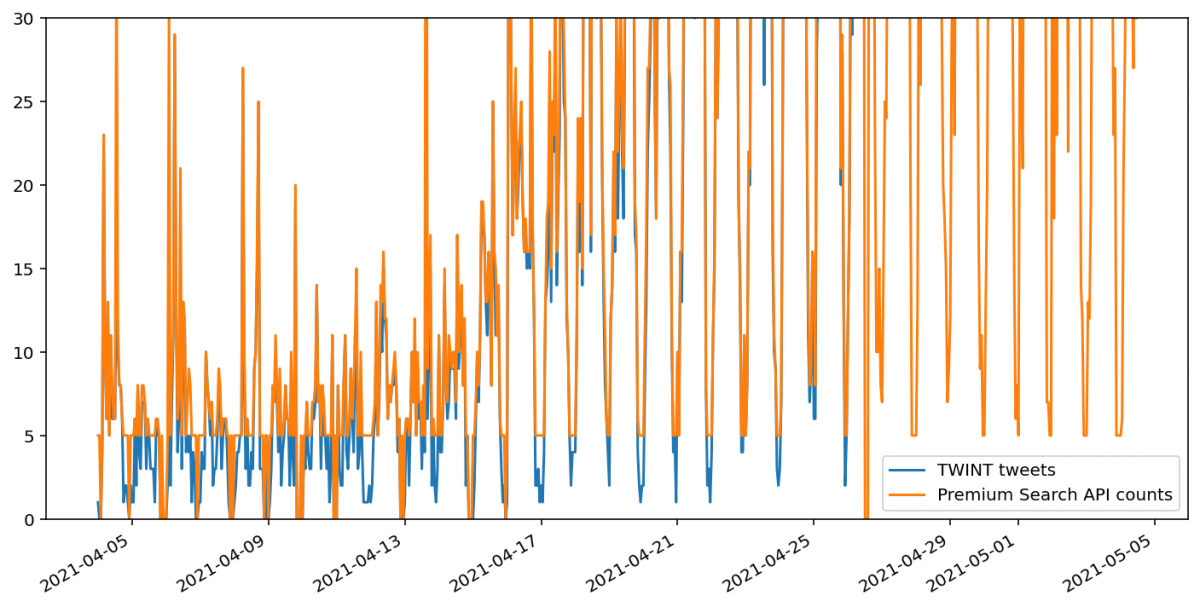
Такое поведение за последнюю неделю (на момент публикации этого материала на английском языке — прим. редактора) соответствует твитам, которые возвращает Premium Search API, но не поиск через Standard Twitter API. Число твитов, подсчитанных таким образом, близко к числу найденных TWINT. Однако некоторые, по-видимому, все-таки отсутствуют.
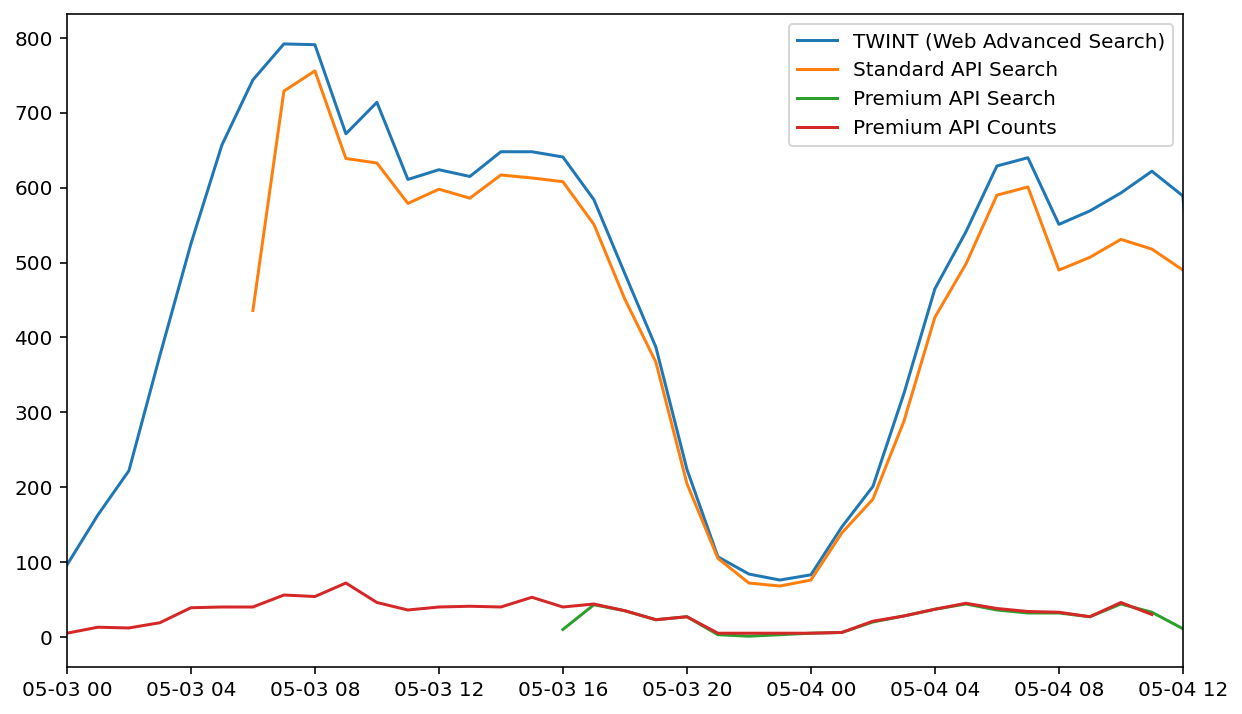
Число твитов за час в результате поиска несколькими различными методами с одним и тем же геокодом. Поиск по стандартному Twitter API ближе к результатам TWINT
Бегло изучив твиты, найденные TWINT, но не Standard API, мы не заметили очевидных причин того, почему последний их не нашел. Получается, что TWINT не только проще в использовании, но и возвращает, по видимому, более полные наборы данных.
Код и данные об этих наблюдениях доступны в Jupyter.
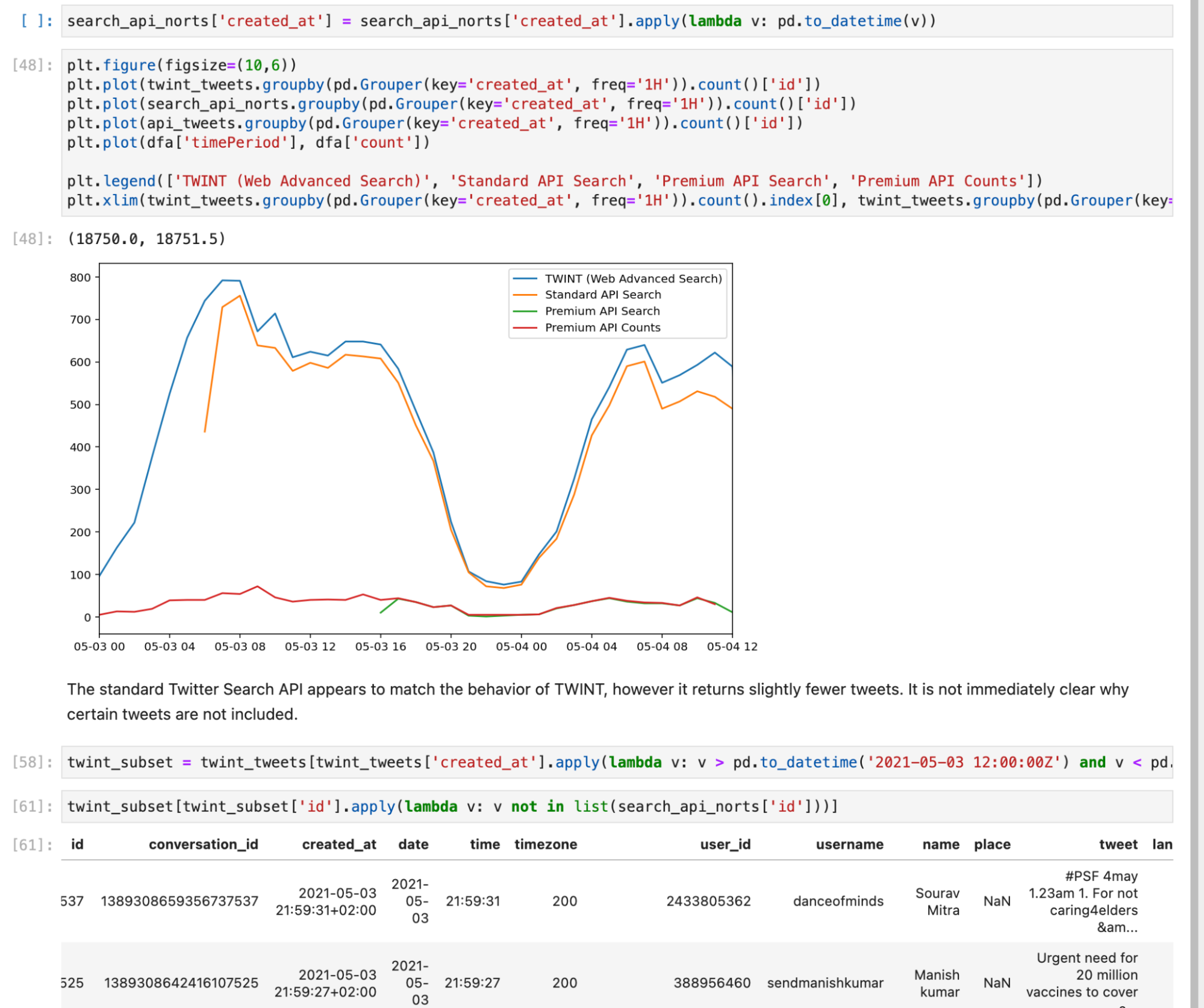
Скриншот из Jupyter, где показано, как были получены и проанализированы данные. Этот блокнот в открытом доступе позволяет независимо воспроизвести наблюдения Bellingcat
Карта частоты твитов и терминов
Чтобы использовать функцию поиска по геокоду для создания карты частоты твитов, нужна шестиугольная сетка из центров поиска. Шестиугольная компоновка — наилучший способ накрыть весь регион при наименьшем перекрытии соседних кругов.
Имеются разные библиотеки для создание шестиугольных сеток. Для этого проекта мы использовали библиотеку H3 от Uber. У нее есть некоторые полезные возможности, например сферическая сетка и построение многоугольников примерно одинаковых размеров. Библиотеки H3 Python содержат методы поиска всех многоугольников, центр которых находится внутри конкретной фигуры. Для этого примера мы использовали примерный контур Индии и ее южноазиатских соседей.
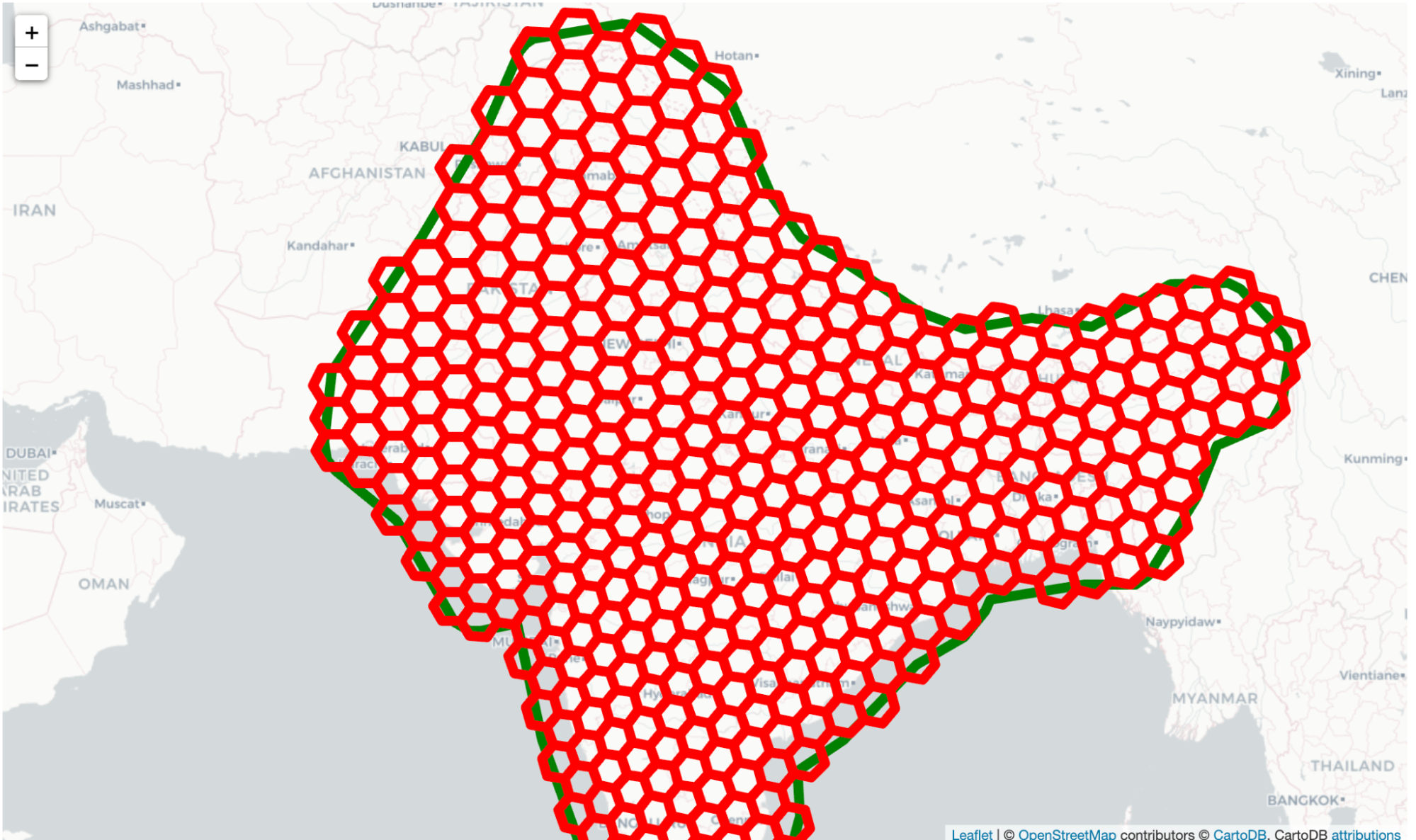
Карта многоугольников, которые попадают в интересующий нас район (в данном случае на территорию Индии и ее соседей, отмечена толстой зеленой линией)
Однако поскольку продвинутый поиск Твиттера позволяет искать только в круглых областях, эти шестиугольники надо преобразовать в накладывающиеся друг на друга круги. Зная площадь каждого многоугольника (которая также доступна в H3), мы расчитали радиус круга, который примерно покрывает его. Радиус и центр каждого многоугольника использовался для создания отдельного поискового запроса. Например, “(urgent OR help) AND geocode:22.089682313298564,81.20150766588854,69.85968148546738km”. Поскольку каждый круг покрывает весь шестиугольник, у краев шестиугольников поисковые запросы будут перекрываться. Это приводит к некоторой потере географической точности. Однако это гораздо меньшая проблема, чем сами по себе ограничения точности геолокации Твиттера.
Далее с помощью TWINT мы скачали результаты поиска для запросов по всем ячейкам и использовали библиотеку Python “pandas” для анализа данных, чтобы сгруппировать твиты по дням и подсчитать их количество. Поскольку в некоторых ячейках содержится куда больше результатов поиска, чем в других, каждая ячейка была нормализована путем расчета базового/нормального количества твитов. В упрощенном виде это среднее значение за весь период.
В Jupyter представлен исходный код, где более подробно изложен этот алгоритм, а также показан экспорт данных в CSV-файлы, которые можно использовать для дальнейшей визуализации.
Скриншот Jupyter, где показано, как эта методика поисковых запросов с геокодами использовалась для построения данных для визуализации
Как мы уже писали и демонстрировали выше, продвинутый поиск Твиттера несколько иначе обходится с твитами за последнюю неделю. Это приводит к появлению искуственного всплеска числа твитов за день. Очевидные способы компенсации этого явления отсутствуют. Поиск по официальному Twitter Search API возвращает более последовательные данные (хотя с меньшим числом твитов), однако они не поддерживают радиус больше 40 км.
В качестве приблизительной компенсации команда Bellingcat использовала разницу количества твитов при поиске за разные промежутки времени, чтобы оценить процент «отсутствующих» твитов за период ранее, чем за прошедшую неделю. Фактически это оценка процента пользователей, у которых в описании профиля приведено местоположение, по сравнению с пользователями, которые используют геотеги в своих твитах. Это корректирующее умножение дает оценку количества твитов, которая ближе к диапазону последней недели. Однако разница этих показателей очень велика, так как она зависит от паттернов постов от пользователей в конкретной географической области. Эту коррекцию умножением следует считать в лучшем случае очень приблизительной. Соответственно, «оценочные» цифры нельзя сравнивать непосредственно с более недавними.
Однако (в той степени, в какой любая выборка является случайной), такие тренды содержания твитов, как процент твитов с определенным ключевым словом, все равно можно сравнивать и за пределами промежутка в одну неделю. Это позволяет изучить, как твиты о необходимости кислорода распространялись из Дели по всей Индии, когда нехватка кислорода стала ощущаться в других городах, а пользователи твиттера из других регионов и стран стали поддерживать просьбы из Дели. В твитах из соседних стран кислород упоминается реже.
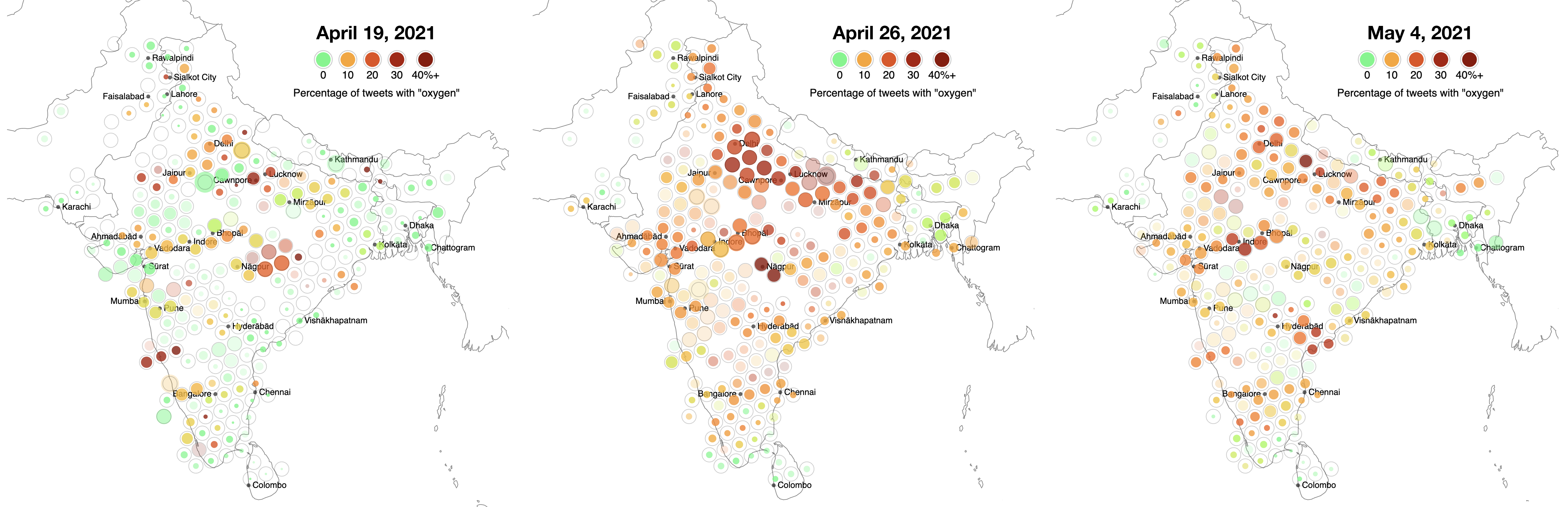
Цветом обозначен процент твитов с просьбами о срочной помощи, где есть ключевые слова, связанные с кислородом. Слева: данные от 19 апреля 2021 года, где видны «горячие точки» в районе Лакхнау и Канпура, а также нарастающий кризис в Дели. Центр: 26 апреля кризис в Дели ухудшился. Во многих других районах Индии также резко выросло число твитов о кислороде, что может быть связано как с местными кризисом, так и с реакцией на ситуацию в Дели. Справа: к 4 мая 2021 года твитов о кислородном кризисе в Дели стало несколько меньше. Однако дор сих пор видны «очаги», например в районе Индора. Нажмите на изображение, чтобы увеличить его
Несмотря на ограничения Twitter API, из твитов все же можно извлечь географическую информацию. Разумеется, эти данные имеют оговорки относительно точности и нерепрезентативной выборки. Но все равно это интересный ресурс для отслеживания мировых события по социальным сетям.
Техническая расследовательская команда Bellingcat разрабатывает инструменты для расследования по открытым источникам и изучает технологические методики исследований. В нее входят Джоанна Уальд, Айганыш Айдарбекова и Логан Уильямс. У вас есть вопрос о применении этих методик или инструментов к вашим собственным исследованиям, или вы заинтересованы в сотрудничестве? Свяжитесь с нами.