
Сбор геопространственных данных веб-скрейпингом
Translations:
Как организации, так и отдельные лица выкладывают в открытый доступ и регулярно обновляют сложные наборы данных, содержащие кладезь ценной информации. Всю эту информацию, за редким исключением, можно загрузить из браузера и преобразовать в удобный для использования формат. Несмотря на то, что она находится в открытом доступе, в большинстве случаев в ее состав также входят скрытые данные, которые невозможно быстро загрузить для дальнейшего анализа. В этом руководстве мы расскажем вам, как при помощи скрейпинга собрать пригодные для изучения геопространственные данные, которые невозможно экспортировать для личного использования простыми и известными способами. Кроме того, мы поговорим о некоторых концептах, связанных с базами данных, которые находятся на публичных серверах и доступ к которым можно получить при помощи API (программного интерфейса приложения).
Это руководство в первую очередь касается загрузки геопространственных данных, но мы надеемся, что некоторые инструкции могут оказаться полезными при работе с другими типами информации, которая хранится аналогичным образом.
Что дает скрейпинг геопространственных данных?
Скрейпинг геопространственных данных может оказаться полезным в нескольких целях, и основная из них — более глубокий анализ.
- Более глубокий анализ
На интерактивной карте, на которой показаны пострадавшие районы в турецких провинциях, где большинство населения составляют курды, можно увидеть масштаб разрушений и местоположение уничтоженных объектов, но после скрейпинга и загрузки данных появляется возможность провести гораздо более глубокий анализ, например установить связь с данными переписи населения или с изображениями аэросъемки, на которых запечатлены импровизированные барьеры, установленные перед проведением операций.
В Интернете также можно найти интерактивную карту разделительного барьера между Израилем и Западным берегом. Загрузив геопространственные данные, вы сможете проанализировать их относительно Зеленой линии 1948 г., создать карту, на которой отмечены «аннексированные» Израилем территории между разделительным барьером и Зеленой линией, или изучить случаи нарушения безопасности в зависимости от их удаленности от барьера.
- Геолокация фото и видео
Скрейпинг также может оказаться полезным при геолокации фото и видео. Если вы анализируете видео из Ливии, на котором видно, как высоковольтные линии передач проходят над автострадой, можно найти интерактивную карту энергетической инфраструктуры этой страны и проанализировать извлеченные из нее данные, чтобы найти все места, где ЛЭП протянуты над автострадой.
- Архивация данных
Помимо дальнейшего анализа, сбор данных скрейпингом может пригодиться для архивации. Подбирая примеры для этой статьи, я попытался найти две известные мне интерактивные карты, на одной из которых отмечены не сопровождавшиеся насилием протесты в Сирии, проводившиеся до начала гражданской войны, а на другой, созданной Caerus Group, — расположение КПП в Алеппо в 2013 г. и информация о контролирующих их группировках. Эти карты больше не поддерживаются, и получить доступ к ним невозможно, а это значит, что отмеченные на них данные, которые, возможно, представляли определенную ценность, утрачены навсегда.
Что нам понадобится
- Google Chrome (в этом браузере есть несколько полезных инструментов, позволяющие выделять пакеты нужных данных, которые затем можно подвергнуть трансформации и преобразовать в обычные файлы, например CSV)
- Notepad++ (или любая другая программа, которая позволяет использовать инструменты поиска по регулярным выражениям)
- Excel, его аналог Google Sheets или другая программа для работы с электронными таблицами
- По желанию – картографическое приложение для визуализации (ArcMap (платное), QGIS или Google Earth Pro)
Следует отметить, что архитектура данных сильно различается, поэтому для представления почти каждого отдельного набора данных требуются разные подготовительные операции. Универсального метода подготовки не существует, но у всех используемых нами программ есть исчерпывающая онлайн-справка, которая поможет вам выполнить любые необходимые действия (это важно, потому что работа с регулярными выражениями не всегда дается легко).
Руководство
Ниже представлена пошаговая инструкция по сбору данных, которые невозможно просто загрузить из сети. В качестве примера приводятся три различных набора данных, начиная с достаточно простого (информация о конфликтах в Ираке, собранная ACLED) и заканчивая более сложными (авиаудары по медицинским учреждениям в Сирии, зарегистрированные организацией Physicians for Human Rights, и карта The Aleppo Project Центрально-Европейского университета).
Данные ACLED
Начнем с такого наглядного примера, как данные из ACLED Dashboard. Эти данные есть в открытом доступе, но мы займемся их извлечением, чтобы посмотреть, насколько небольшой объем обработки потребуется.
Для начала нажимаем правой клавишей мыши на любое место страницы и выбираем «Просмотреть код». Если вы работаете на компьютере, можно также воспользоваться комбинацией клавиш Ctrl+Shift+i.
После того как откроется диалоговое окно, переходим на вкладку Network («Сеть»). Она выглядит примерно так.
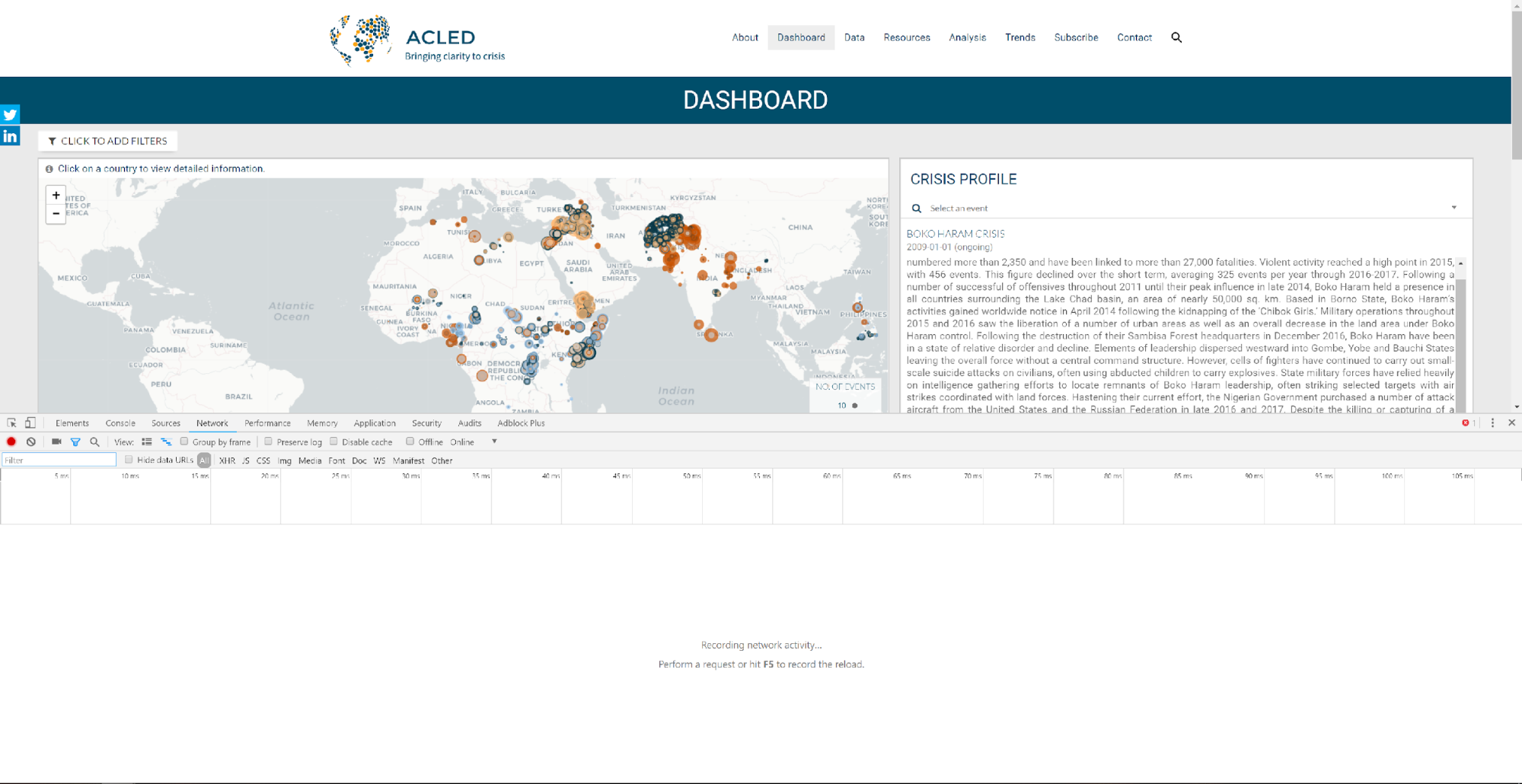
Загрузка данных
Находим на карте Ирак. Увеличивая и передвигая карту, мы видим, как в открытом снизу окне на вкладке Network («Сеть») меняются пронумерованные изображения в формате PNG – это составные элементы картографической подложки. На этой вкладке отображаются все файлы и скрипты, которые сайт запускает или загружает по мере того, как мы просматриваем информацию в браузере. В коде сайта скрываются скрипты, которые инициируют загрузку еще большего количества данных. Мы видим их на вкладке Network («Сеть») в столбце Initiator («Инициатор»). Так, файлы с изображениями PNG инициируются leaflet.js:5, который сообщает Carto, какие файлы мы хотим просмотреть.
На карте нажимаем на Ирак, чтобы загрузить только те события, которые связаны с этой страной. Теперь мы видим файл, название которого начинается с read.csv, – это и есть нужные нам данные, и файл связывает нас со следующим URL-адресом:
Давайте посмотрим, что нам дает эта ссылка.
Во-первых, она дает нам доступ к API ACLED, который, в свою очередь, позволяет нам направить запрос к оперативной базе данных для загрузки интересующей нас информации. У каждого API есть руководство пользователя (User Guide), где написано, что можно сделать с помощью этого конкретного интерфейса. У ACLED, в отличие от большинства других баз данных, имеется собственный API. Большая часть наборов данных представляет собой единые базы данных или таблицы, для которых используются сторонние API. Но пока давайте сосредоточимся на простом наборе данных ACLED. Если просто ввести ссылку https://api.acleddata.com/acled/read.csv в браузер, автоматически начнется загрузка файла CSV, который содержит последние 500 событий, внесенных в базу данных ACLED. Этот файл можно открыть для просмотра в Excel или любой другой программе для работы с электронными таблицами.
Та часть URL-адреса, которая следует за read.csv, сообщает интерфейсу API, что мы хотим. Limit=0 означает, что запрос возвращает все соответствующие данные. Это значение можно заменить на любое другое в зависимости от того, сколько строк мы хотим загрузить. Следующая часть URL ограничивает поиск определенным государством. Здесь мы можем изменить название государства или добавить другие параметры. Например, если вставить &event_type=Riots/Protests между Iraq и &fields, будут загружены только события, помеченные как Protest (протесты) или Riots (восстания). Аналогично можно поступить с actor (вовлеченная сторона) и location (место события). Например, при использовании следующей ссылки
будут загружены только те события, которые произошли в Мосуле.
Та часть URL, которая следует за &fields=, сообщает API, какие столбцы следует загрузить. Это важный момент, потому что он более характерен для баз данных, не располагающих собственным выделенным API. %7C – это зашифрованный в виде текста символ «|», который служит для разделения столбцов. В нашем случае загружены будут столбцы iso, actor1, actor2, event_date, event_type и т. д. Если определенные столбцы нам не нужны, мы можем удалить их URL, чтобы упростить загружаемый набор данных. В этом случае у нас есть документация по API, поэтому мы можем также добавить другие столбцы, например %7Ccountry%7Cnotes, чтобы получить больше информации.
В качестве упражнения попробуйте определить, какие события будут загружены, если вы воспользуетесь следующей ссылкой:
Затем загрузите файл CSV и проверьте, верны ли ваши предположения. Нам нужен файл CSV, включающий все столбцы с важной информацией, в том числе с долготой и широтой, чтобы импортировать его в Google Earth Pro или любую другую программу GIS.
Атаки на медицинские учреждения в Сирии
Давайте попробуем кое-что посложнее.
Организация Physicians for Human Rights (Врачи за права человека) ведет интерактивную карту атак на медицинские учреждения в Сирии. Карта довольно подробная, и если нажать на определенное событие, то появляется дополнительная информация о нем. Все эти данные можно загрузить при помощи скрейпинга.
- Снова выбираем «Просмотреть код» и переходим на вкладку Network («Сеть»).
- Обновите страницу, чтобы выполнить скрейпинг всей информации, которая появляется при загрузке. Здесь мы видим более сложный список. Нам придется постараться, чтобы найти нужный файл. В целом искать можно по JOSN, CSV и SQL, и один из результатов будет содержать нужные нам данные, но в этом случае единственный подходящий результат – это SQL, который позволяет выполнить загрузку разбитой на фрагменты картографической подложки с сервера.
Иногда приходится действовать, следуя интуиции, проверять файлы и менять запрос таким образом, чтобы загрузить больше информации по интересующей нас теме. В этом случае мне удалось найти нужные данные, нажав на одну из отмеченных на карте атак и открыв дополнительную информацию о ней. В окне внизу страницы появился новый файл SQL, который, в моем случае, имеет следующее название:
sql?q=select%20%22area%22%2C%22area_of_control%22%2C%22attack_description%22%2C%22city%22%2C%22date%22%2C%22date_stamp%22%2C%22deaths%22%2C%22exact_location%22%2C%22facility_type%22%2C%22field_61%22%2C%22field_source1%22%2C%22field_source2%22%2C%22governorate%22%2C%22hospital_name%22%2C%22hospital_type%22%2C%22image1_caption%22%2C%22image1_link%22%2C%22image1_source_caption%22%2C%22image1_source_link%22%2C%22image2%22%2C%22image2_caption%22%2C%22image2_link%22%2C%22image2_source_caption%22%2C%22image2_source_link%22%2C%22injuries%22%2C%22latitude%22%2C%22longitude%22%2C%22mode_of_attack%22%2C%22no_dead%22%2C%22no_injured%22%2C%22outcome_for_facility%22%2C%22perpetrator%22%2C%22source1_caption%22%2C%22source1_link%22%2C%22source1_period%22%2C%22source2_caption%22%2C%22source2_link%22%2C%22source2_period%22%2C%22source3_caption%22%2C%22source3_link%22%2C%22source3_period%22%2C%22source_type%22%2C%22total_no_of_attacks%22%2C%22video1%22%2C%22video1_caption%22%2C%22video1_code%22%2C%22video2%22%2C%22video2_caption%22%2C%22video2_code%22%2C%22video2_link%22%2C%22video3%22%2C%22video3_caption%22%2C%22video3_code%22%2C%22video3_link%22%2C%22video4%22%2C%22video4_caption%22%2C%22video4_code%22%2C%22video4_link%22%2C%22video_footage%22%2C%22video_height%22%2C%22weapons_used%22%20from%20(select%20*%20from%20facilityattacks_2017_12_update)%20as%20_cartodbjs_alias%20where%20cartodb_id%20%3D%20287
Открыв эту ссылку в новой вкладке, мы видим, что она дает нам доступ к одной-единственной записи из базы данных SQL. Здесь %20– это пробел, %22 – кавычка, а %2C – запятая. Изучив URL, мы видим, что в этом API сначала перечисляются поля, которые следует отобразить, а затем из всей базы выбирается where cartodb_id = 20287, что в итоге ограничивает результаты поиска одной записью.
URL-адрес можно поменять, удалив это ограничение и ненужные поля. Я, например, изменил его следующим образом:
Доступа к руководству пользователя по базе данных у нас нет, поэтому добавить дополнительные поля мы можем только на основе собственных догадок.
Синтаксический анализ данных
Когда мы переходим по этой ссылке, то загрузка файла не начинается – вместо этого текст открывается непосредственно в браузере. Начинаем подготовку данных.
Открываем Notepad++ и вставляем в новый документ полностью весь текст. Для начала давайте разберемся, как эти данные организованы и что нужно сделать, чтобы перенести их в Excel или другую программу для работы с электронными таблицами. В полях data («дата») и description («описание») значатся достаточно длинные параметры, содержащие запятые, поэтому мы не можем подготовить эти данные в виде обычного файла CSV.
Давайте представим их в виде таблицы, где строки разделены символом |. Для этого нам нужно убрать метки данных, которые стоят перед каждой записью, например “hospital_name”:,, вывести их в заголовок и разделить все значения при помощи |.
Подготовка данных
Первое, что нам нужно сделать, — перенести каждую запись в отдельную строку. Мы видим, что элементы данных отделены друг от друга с использованием фигурной скобки }. Здесь нам придется прибегнуть к помощи регулярных выражений. Это не всегда просто, но, к счастью, почти все можно найти поиском в Google, и в большинстве случаев кто-то уже написал нужный нам код.
Открываем диалоговое окно замены при помощи комбинации клавиш Ctrl+H (на компьютере). В этой статье я для удобства называю функцию замены «найти|заменить».
Чтобы разбить текст на отдельные строки, вводим “\},\{|\n” и включаем режим поиска по регулярным выражениям. Это поможет нам найти все фигурные скобки, { или }, и заменить их на переход на новую строку. \ означает, что мы ищем скобки как символ, а не используем их как функцию, а \n создает переход на новую строку. Удалив ненужные отрезки кода в начале и в конце текста, мы получим 492 строки, каждая из которых содержит отдельный элемент данных.
Теперь разделим строки символом | и удалим из каждой строки отдельные метки. Для этого заменим весь текст между кавычками, после которых стоит двоеточие. То есть мы заменяем “,”(.*?)”:|,” на (.*?), или, другими словами, любое количество символов, которое стоит после ,” и перед “:.
Прежде чем это сделать, давайте подумаем, как нам разделить поля после замены. Между полями будет стоять ““,””, за исключением случаев с цифрами и значениями null, true и false. Давайте вернемся в браузер и посмотрим в самый низ вкладки с кодом. Там мы увидим список рядов и их типов: string (строка), boolean (логическое, или булевое значение) и number (число). Строки и логические значения указываются без кавычек, а значит, разделить их будет сложнее.
Заключим их в кавычки, чтобы сделать нашу задачу проще. Снова воспользуемся функцией замены. Для чисел введем “”:(\d.*?),| “:”\1”,”. Это поможет нам поменять все числа в скобках, за которыми стоит “:, на те же числа, но в кавычках. Все прочие команды, такие как “true|”true”” или “null|”null””, в основном не представляют сложностей.
Теперь удалим из каждой записи метки строк, воспользовавшись упомянутой выше формулой “,”(.*?)”:|,”, и, наконец, разделим строки символом “”,”|”|””. Затем попробуем удалить метку из первой строки при помощи “”area”:|”.
Теперь наш текст выглядит примерно так:

Остался последний этап подготовки, после чего данные можно будет скопировать в Excel. Возвращаемся в браузер, находим URL-адрес и выбираем заголовки строк:
area%22%2C%22area_of_control%22%2C%22attack_description%22%2C%22city%22%2C%22date%22%2C%22deaths%22%2C%22exact_location%22%2C%22facility_type%22%2C%22hospital_name%22%2C%22hospital_type%22%2C%22injuries%22%2C%22latitude%22%2C%22longitude%22%2C%22mode_of_attack%22%2C%22no_dead%22%2C%22no_injured%22%2C%22outcome_for_facility%22%2C%22perpetrator%22%2C%22total_no_of_attacks%22%2C%22weapons_used
22%2C%22total_no_of_attacks%22%2C%22weapons_used
Копируем этот фрагмент и вставляем его самое начало документа Notepad++, после чего заменяем закодированные цифрами символы, например “%22%2C%22||”, на | .
Копирование в Excel
Пришло время воспользоваться Excel или другой программой для работы с электронными таблицами, чтобы убедиться в том, что мы все подготовили правильно. Копируем весь текст и вставляем его в новый лист в Excel, затем переходим на вкладку «Данные» и выбираем «Текст по столбцам». Нажимаем «с разделителями», отмечаем «Другой» и вводим |. Нажимаем «Готово». Вернувшись на лист, куда мы вставили текст, проверяем, чтобы все строки были равномерно разделены по столбцам. Вся таблица должна выглядеть выровненной, например вот так:
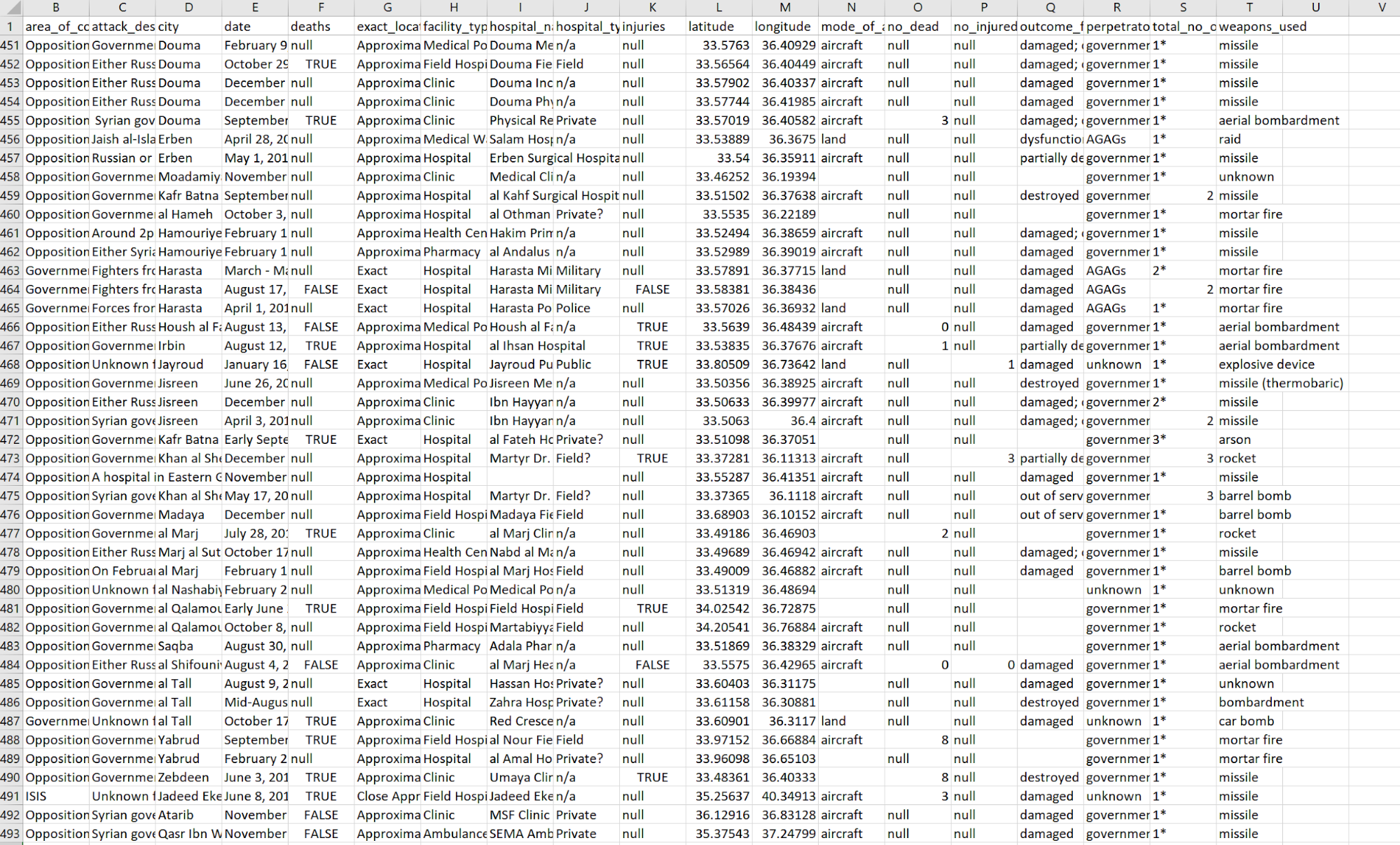
Итак, мы закончили синтаксический анализ данных и теперь можем изучить их любым нужным нам способом. Первое, что мы сделаем, – заменим все null на соответствующие значения (False в столбцах F и K, 0 в столбцах O и P).
Анализ данных
Например, мы хотим составить диаграмму, представляющую наиболее опасные виды вооружения, которые использовались для атак на медицинские учреждения. Для этого создадим новый столбец, где будет указано количество жертв. Составив сводную таблицу, мы увидим, что наиболее опасным видом оружия являются Car Bombs (заминированные автомобили).
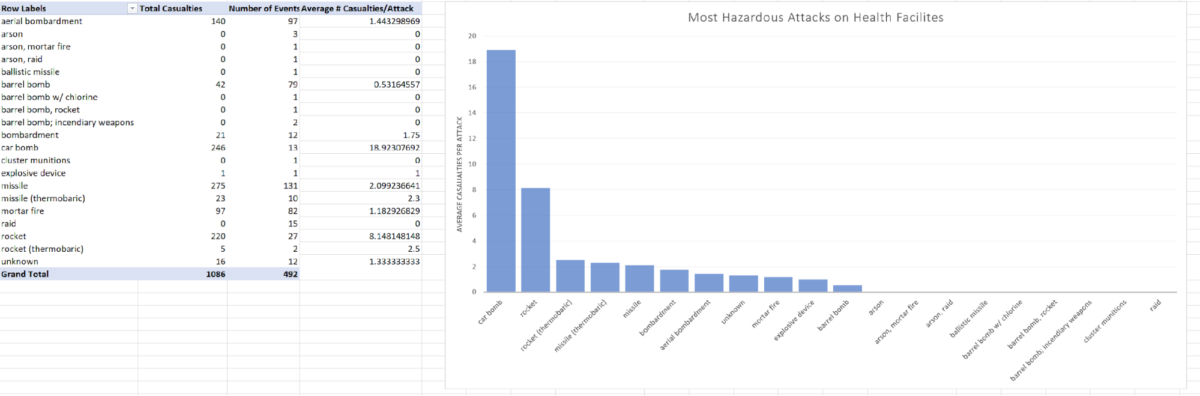
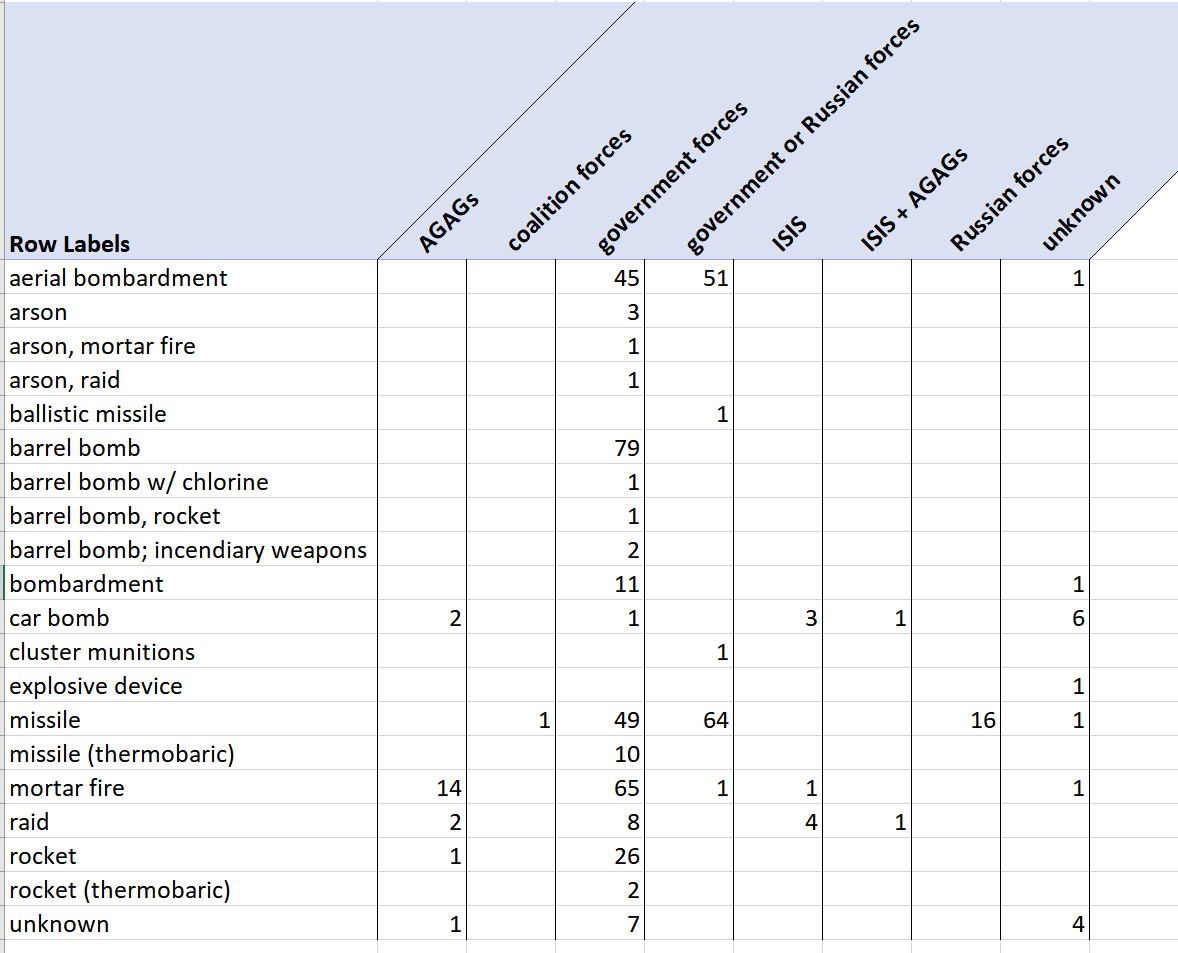
Мы также видим, что большая часть заминированных автомобилей не имеет связи ни с какими определенными сторонами, однако те из них, принадлежность которых была установлена, в основном принадлежали ISIS (ИГ). AGAG в этом наборе данных означает anti-government armed group, или «вооруженные группировки, выступающие против правительственных сил».
Эти данные можно импортировать в любую другую программу. Например, мы решили исследовать скрипичные диаграммы примененного оружия и соответствующего количества жертв. Для этого импортируем данные в R Studio. В этой программе намного больше возможностей для построения различных графиков и диаграмм, позволяющих обобщать данные:
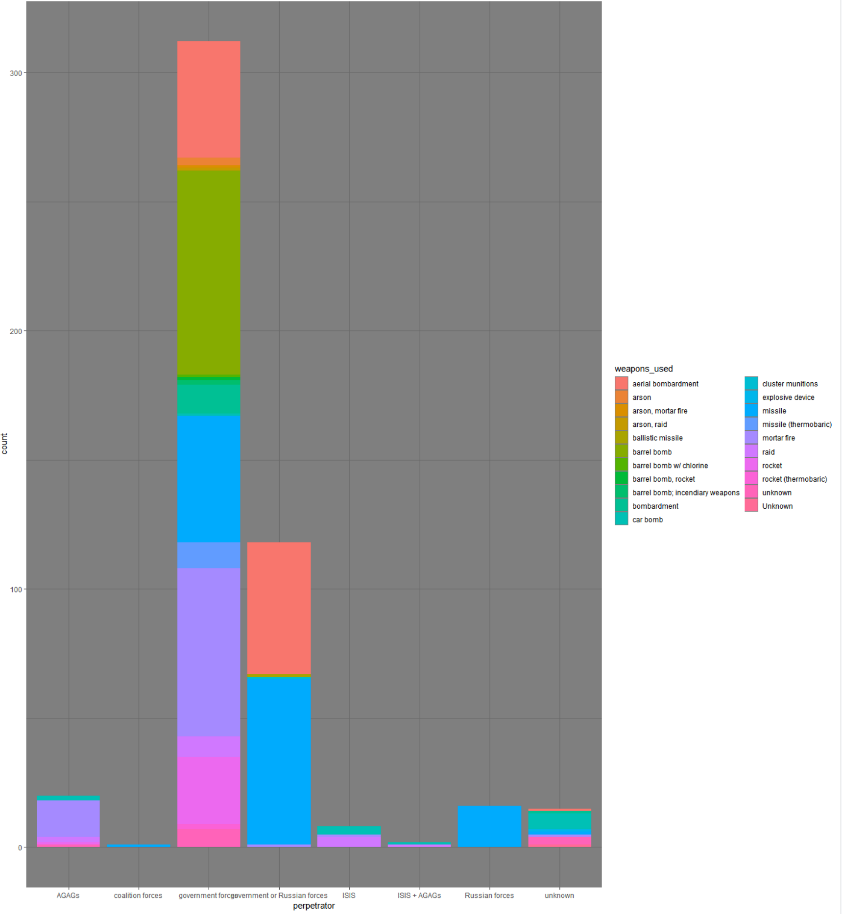
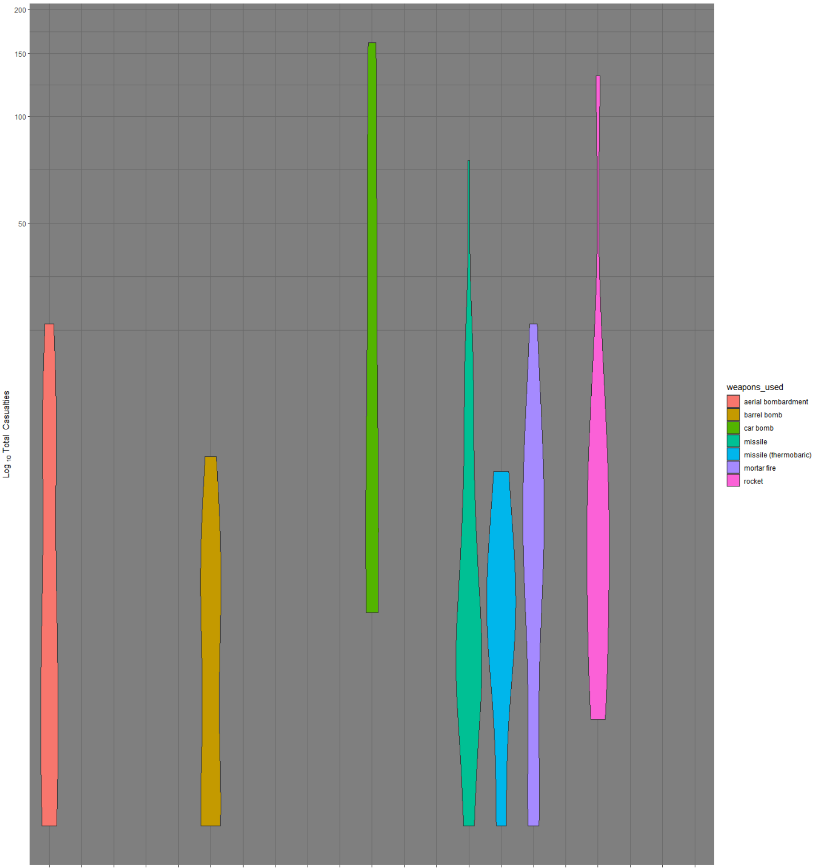
Собранная нами информация представляет собой геопространственные данные, поэтому мы также можем использовать поля, содержащие широту и долготу, чтобы импортировать их в картографическую программу, например в Google Earth Pro или в другую геоинформационную систему, допустим, ArcMap.
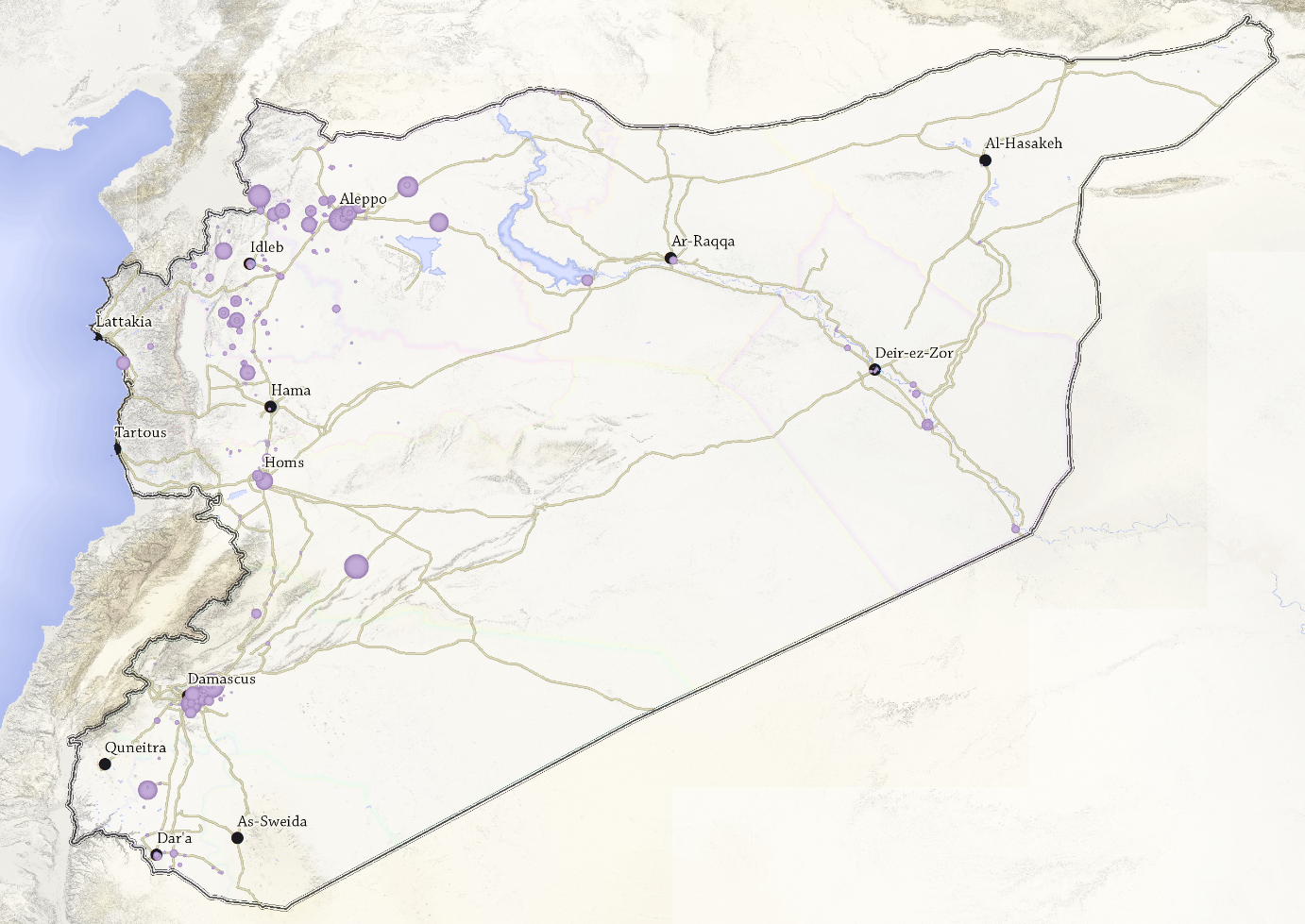
Извлечение полигональных объектов (районы Алеппо)
Наконец, обратимся к более сложным операциям с геопространственными данными. Здесь мы уже имеем дело не с точками, а с полигонами. Это пригодится нам в том случае, если наше исследование непосредственно касается контроля территорий или если мы хотим извлечь определенные элементы. В качестве примера рассмотрим подробную карту Алеппо. Ее составили сотрудники Aleppo Project, вот ссылка.
Чтобы на карте отобразились районы города, поставьте галочку напротив соответствующей опции в меню, расположенном в правом верхнем углу карты. Скорее всего, для вас уже не составит труда найти географические данные в этом наборе (ищите запись, где упоминаются JSON и маркер доступа), но если что-то не получается, просто воспользуйтесь этой ссылкой. Мы сразу видим, что данные похожи на предыдущий пример с атаками на медицинские учреждения, но в них намного больше географических координат.
Well-Known Text
Прежде чем мы приступим к подготовке, хотелось бы отметить одну вещь. В этом примере мы изучаем более сложные геометрические объекты на карте, поэтому нам необходимо будет ознакомиться с форматом Well-Known Text (WKT), который используется для хранения векторных фигур (фигур, определяемые на карте при помощи координат их вершин) в текстовом формате, похожем на обычный код XML. Эти данные можно импортировать во множество разных программ, но мы воспользуемся Google Earth Engine, потому что к ней легко получить доступ и потому что WKT – один из ее родных форматов. Если нарисовать в Google Earth любой полигон, сохранить его как файл KML и открыть в Notepad, мы увидим полигон в формате WKT.
Подготовка данных
Первым делом при помощи уже известных нам регулярных выражений поместим каждый элемент в отдельную строку. Я решил заодно убрать ненужные и порядком раздражающие данные, указанные перед каждой записью, поэтому я воспользовался “\{“type”:”Feature”,”properties”:\{|”. Кроме того, в это случае нам понадобятся только имя и координаты каждого файла. Иногда при работе с фоновыми картограммами может также потребоваться извлечение элементов, но мы пока не будем отвлекаться на эту задачу и пойдем по простому пути. Можно удалить и многие другие поля, например, если использовать “”,”NAME_A”:”(.*?)”,”title”:”(.*?)”,”description”:”(.*?)”,”marker-color”:””,”marker-size”:””,”marker-symbol”:””,”stroke”:”#000000″,”stroke-width”:1,”stroke-opacity”:1,”fill”:”#6c6c6c”,”fill-opacity”:0.20000000298023224\},”geometry”:\{|”, “\],”type”:”Polygon”\},”id”:”(.*?)”\},|” и прочие регулярные выражения. Я структурировал данные таким образом, чтобы каждый объект занимал три строки: первая содержит его имя, вторая — координаты, а третья остается пустой и служит для наглядного отделения объектов друг от друга.

Теперь нам нужно отформатировать координаты для того, чтобы их можно было использовать в Google Earth. В формате Well Known Text они представлены в виде “long,lat,elev long,lat,elev long,lat,elev” и т. д., где long — долгота, lat — широта, а elev — высота. Сложного здесь ничего нет, просто заменяем “\],\[|,0 “. Затем удаляем открывающую квадратную скобку, а закрывающую квадратную скобку превращаем в “,0”.
Конвертация в файл KML
Данные подготовлены, теперь давайте конвертируем их в файл KML. Возвращаемся к тому самому полигону KML, который мы создали раньше, открываем его с помощью Notepad и заменяем всю информацию с тегами <name> («имя») на данные из первой строки, вместе с тегами <coordinates> («координаты»).
Осталось только вставить нужные координаты и сохранить файл в формате KML.
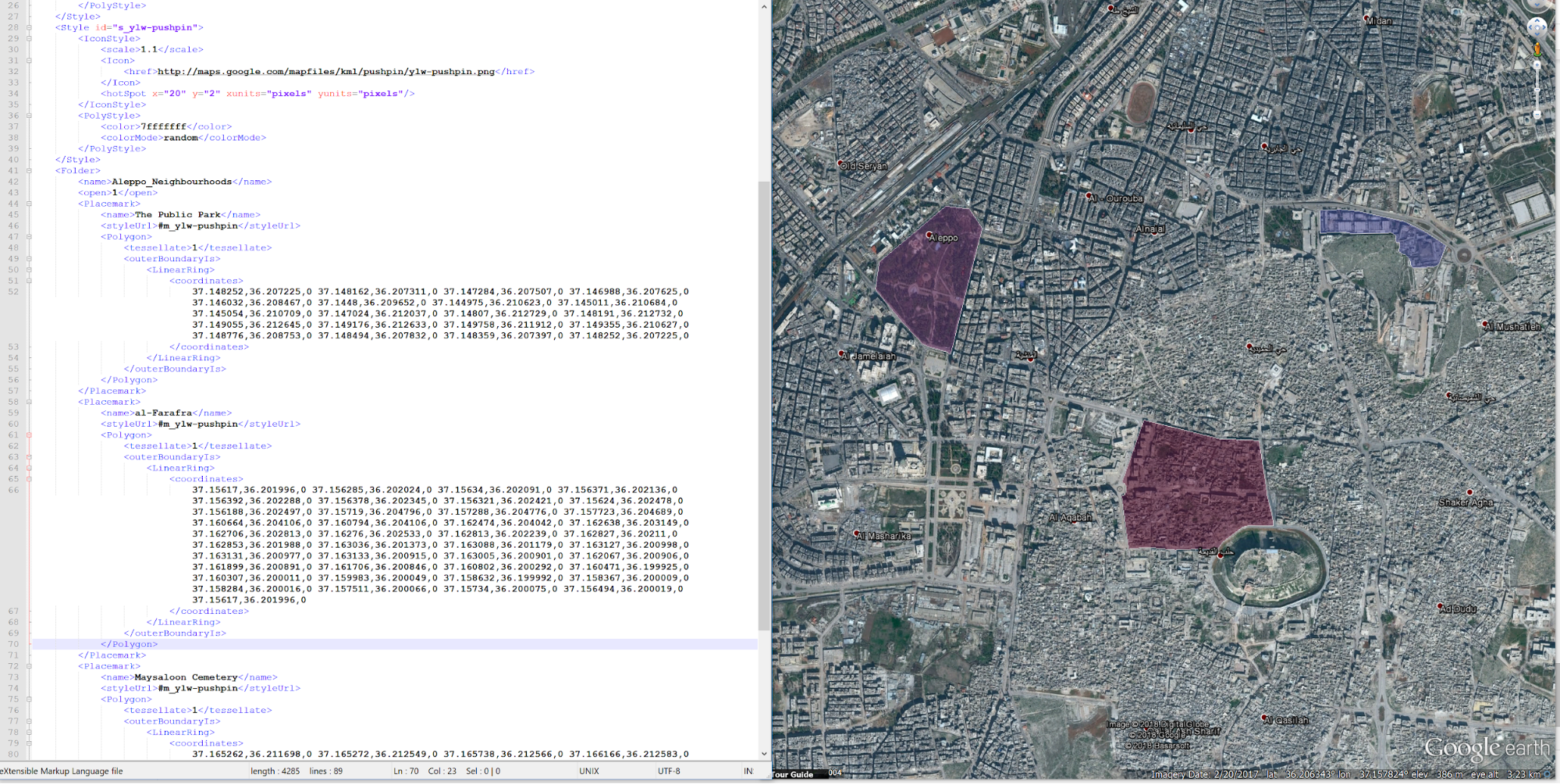
Если требуется импортировать небольшое количество элементов, их можно запросто скопировать и вставить в файл KML вручную, но если вам нужны все элементы, то удобнее будет переформатировать весь набор данных и превратить его в файл KML со множеством элементов.
Заменяем “\n([A-Z|a-z])|\n|\1”, “([a-z])\n|\1\?\n”, “\n([0-9])|\n\!\1”, “([0-9])\n|\1#\n”.
Эти команды помогут нам добавить маркеры начала и конца каждой строки, таким образом, позже мы сможем вставить их в формат XML файла KML. Теперь каждая запись, состоящая из двух строк, выглядит следующим образом:

Воспользуемся многострочными командами замены, чтобы добавить все элементы в KML. Наверное, проще всего будет просто скопировать и вставить все то, что я написал ниже, или же скопировать информацию непосредственно из открытого файла KML, на котором мы тренируемся.
- “\|| <Placemark>\n <name>”. Заменяет все символы | на указанный код.
- “\?|</name>\n <styleUrl>#m_ylw-pushpin</styleUrl>\n <Polygon>\n <tessellate>1</tessellate>\n <outerBoundaryIs>\n <LinearRing>”. Аналогичным образом, эта команда заменяет символ ? на указанный код, а следующие две команды делают то же самое с символами ! и #.
- “\!| <coordinates>\n “
- “0\#|0\n </coordinates>\n </LinearRing>\n </outerBoundaryIs>\n </Polygon>\n </Placemark>\n”
- “</Placemark>\n\n <Placemark>|</Placemark>\n <Placemark>”. Эта команда удаляет пустые строки между строками с кодом XML.
Обратите внимание, что в приведенных выше строках нужно копировать полностью весь текст, все символы и все знаки табуляции между | и закрывающими кавычками.
Копируем и вставляем открывающие и закрывающие теги из файла KML. Для этого лучше всего воспользоваться файлом KML, на котором мы тренируемся. Теги эти выглядят примерно так:
<?xml version=”1.0″ encoding=”UTF-8″?>
<kml xmlns=”http://www.opengis.net/kml/2.2″ xmlns:gx=”http://www.google.com/kml/ext/2.2″ xmlns:kml=”http://www.opengis.net/kml/2.2″ xmlns:atom=”http://www.w3.org/2005/Atom”>
<Document>
<name>tmp.kml</name>
<StyleMap id=”m_ylw-pushpin”>
<Pair>
<key>normal</key>
<styleUrl>#s_ylw-pushpin</styleUrl>
</Pair>
<Pair>
<key>highlight</key>
<styleUrl>#s_ylw-pushpin_hl</styleUrl>
</Pair>
</StyleMap>
<Style id=”s_ylw-pushpin_hl”>
<IconStyle>
<scale>1.3</scale>
<Icon>
<href>http://maps.google.com/mapfiles/kml/pushpin/ylw-pushpin.png</href>
</Icon>
<hotSpot x=”20″ y=”2″ xunits=”pixels” yunits=”pixels”/>
</IconStyle>
<PolyStyle>
<color>7fffffff</color>
<colorMode>random</colorMode>
</PolyStyle>
</Style>
<Style id=”s_ylw-pushpin”>
<IconStyle>
<scale>1.1</scale>
<Icon>
<href>http://maps.google.com/mapfiles/kml/pushpin/ylw-pushpin.png</href>
</Icon>
<hotSpot x=”20″ y=”2″ xunits=”pixels” yunits=”pixels”/>
</IconStyle>
<PolyStyle>
<color>7fffffff</color>
<colorMode>random</colorMode>
</PolyStyle>
</Style>
<Folder>
<name>Aleppo_Neighbourhoods</name>
<open>1</open>
Это были открывающие.
</LinearRing>
</outerBoundaryIs>
</Polygon>
</Placemark>
</Folder>
</Document>
</kml>
А это закрывающие.
Теперь сохраняем файл в формате KML (в раскрывающемся меню выбираем eXtensible Markup Language File и заменяем xml на kml в диалоговом окне сохранения) и открываем его в Google Earth, чтобы проверить, нет ли ошибок.
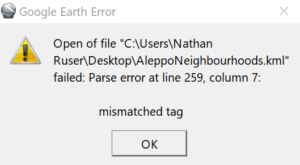
Чтобы диагностировать ошибку, находим строку 259 и смотрим, что с ней не так. Это несложно заметить на показанном ниже скриншоте:

Строка заканчивается скобкой “)”, поэтому когда мы проставляли теги с помощью функции найти и заменить, конечный маркер имени (“?”) в нее добавлен не был. Таким образом, между тегом <name> («имя») и тегом <coordinates> («координаты») пропущены несколько строк кода XML. Самый простой способ исправить эту ошибку — скопировать и вставить пропущенные строки вручную, но если у вас в наборе данных много имен, заканчивающихся закрывающей скобкой, можно добавить конечный маркер имени при помощи функции найти и заменить, например, воспользовавшись командой “([a-z]|\))\n|\1\?\n”. У меня в файле эта ошибка встречалась еще только в 6 или 7 случаях, и я везде исправил ее, скопировав и вставив недостающие строки вручную.
Наконец мы собрали все полигональные объекты в одном файле формата KML, который можно открыть в Google Earth или в любой другой программе GIS.
Итак, мы рассмотрели несколько примеров того, как веб-скрейпингом собрать геопространственные данные из открытых источников для дальнейшего анализа. Эта методика подходит для большинства наборов данных, представленных на интерактивных картах. Есть и исключения: на платформах ArcGIS и QGIS базовые данные скрыты за счет использования протокола Web Map Server, и загрузить их невозможно. Кроме того, почти в каждом наборе данных существует собственная организационная структура. Надеюсь, эта статья поможет вам приобрести начальные навыки в области скрейпинга, но не забывайте, что в любом наборе данных есть свои сложности. Найдите интерактивную карту, которая вас заинтересует, и посмотрите, какие данные вы сможете из нее извлечь.
Если хотите попотеть над по-настоящему сложной задачей, вот самый хитрый набор данных, который я видел в своей жизни: база данных происшествий, связанных с преступностью, в Автономном регионе Мусульманского Минданао.
Какие бы данные вы ни решили собирать и анализировать — удачи! Не забывайте ссылаться на источник геопространственных данных, когда говорите о них или о результатах их анализа. И учтите, что если вы захотите использовать информацию в коммерческих целях, для этого необходимо получить прямое разрешение куратора соответствующей базы данных.

